Training Universal Vocoders with Feature Smoothing-based Augmentation Methods for
High-quality TTS Systems
Abstract
While universal vocoders have achieved proficient waveform generation across diverse voices, their integration into text-to-speech (TTS) tasks often results in degraded synthetic quality. To address this challenge, we present a novel augmentation technique for training universal vocoders. Our training scheme randomly applies linear smoothing filters to input acoustic features, facilitating vocoder generalization across a wide range of smoothings. It significantly mitigates the training-inference mismatch, enhancing the naturalness of synthetic output even when the acoustic model produces overly smoothed features. Notably, our method is applicable to any vocoder without requiring architectural modifications or dependencies on specific acoustic models. The experimental results validate the superiority of our vocoder over conventional methods, achieving 11.99% and 12.05% improvements in mean opinion scores when integrated with Tacotron 2 and FastSpeech 2 TTS acoustic models, respectively.
- Last update: 26 Mar 2024
Table of Contents
Systems
Vocoder Training Methods
- ST: Universal vocoder separately trained (ST) from acoustic models using the ground-truth acoustic features
- FT: Speaker-dependent vocoder fine-tuned using the corresponding acoustic model's generation
- ST-SA (Proposed): Universal vocoder separately trained with the proposed smoothing augmentation (SA) method (shown in Figure 1(b))

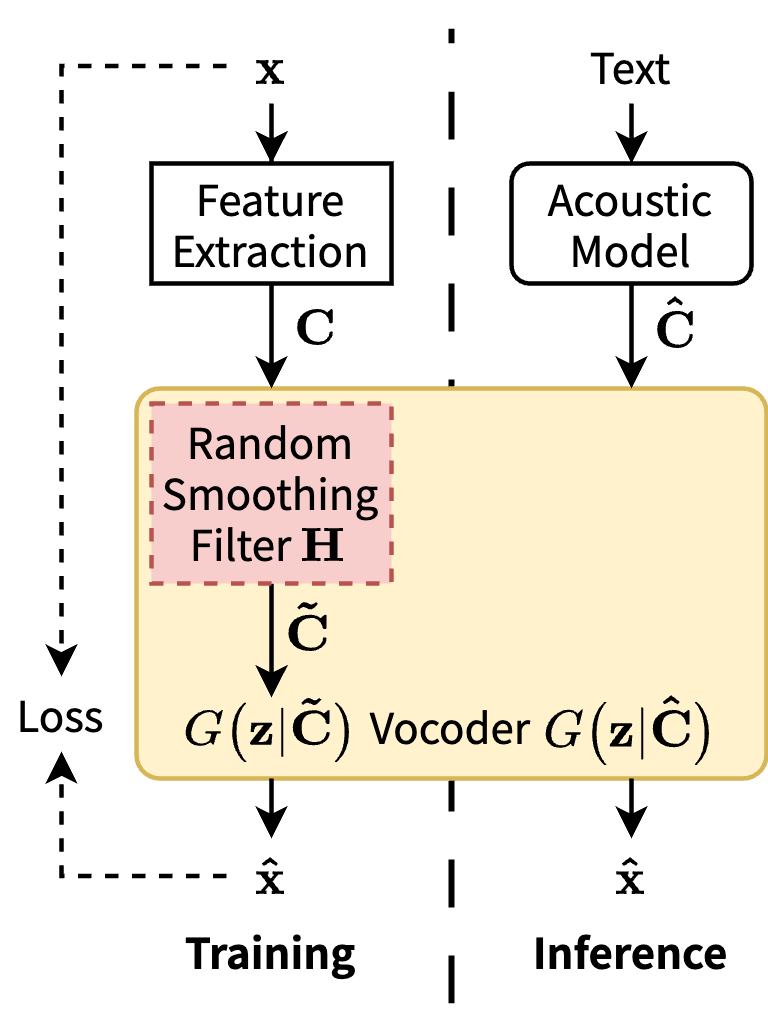
Figure 1: Block diagram of the vocoding process in the TTS framework: (a) ST and (b) ST-SA (Proposed).
Vocoder Models
- HiFi-GAN V1 [1]
- UnivNet-c32 [2]
- eUnivNet (Proposed): UnivNet-c16 + harmonic-noise generator (HN-G) + MS-STFT/CoMB discriminators (M/C-D) (shown in Figure 2(b))
- eUnivNet-HN-G: eUnivNet only with HN-G (without M/C-D)
- eUnivNet-M/C-D: eUnivNet only with M/C-D (without HN-G)
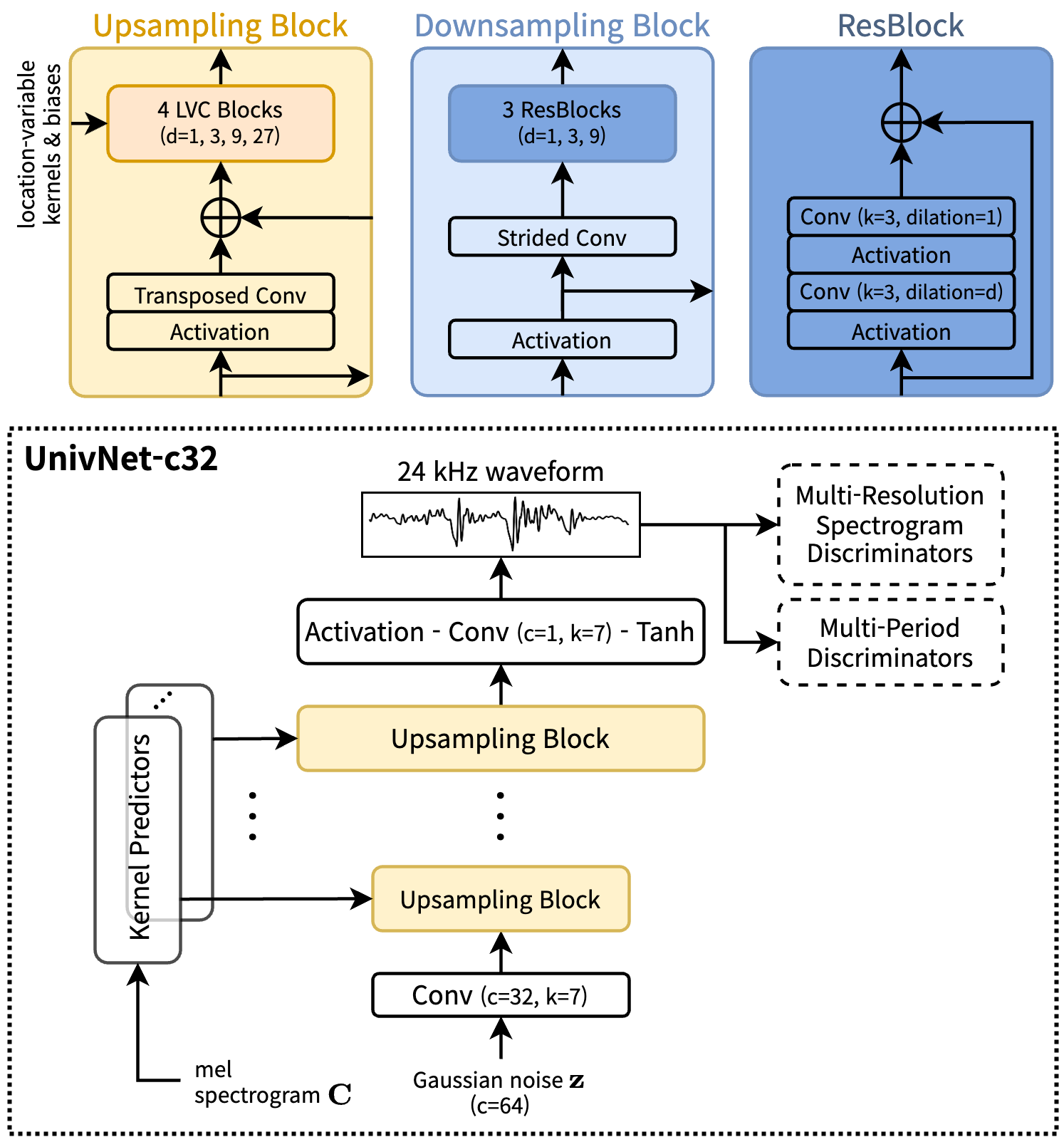
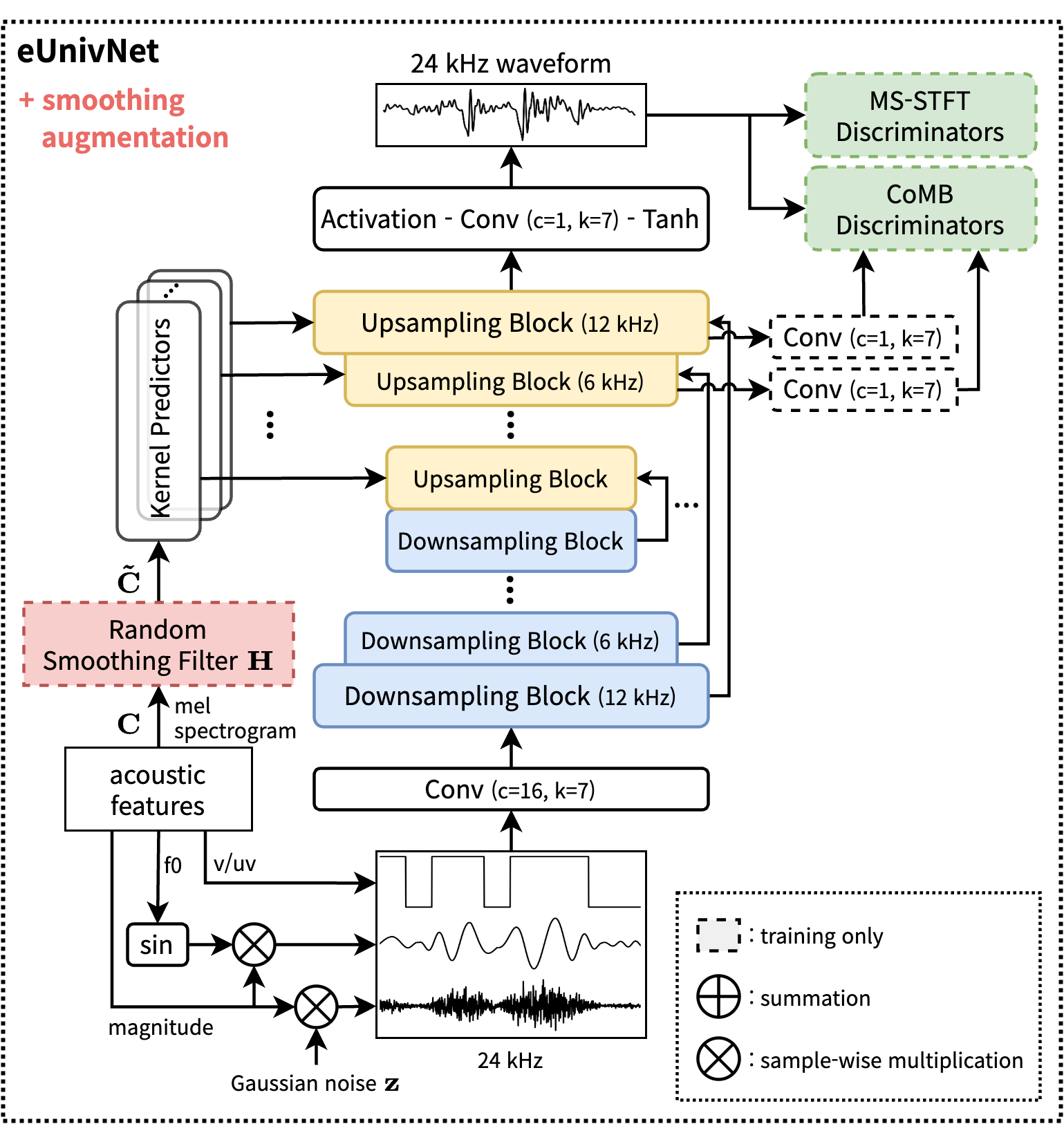
Figure 2: The UnivNet architectures: (a) the vanilla UnivNet-c32 model and (b) the proposed eUnivNet model. The notations c and k denote the number of channels and the kernel size of the convolution layer, respectively.
Training Method Comparison
Tacotron 2 + eUnivNet
| Seen Speakers | Recording | ST | FT | ST-SA (Proposed) |
|---|---|---|---|---|
| F1 | ||||
| F2 | ||||
| M1 | ||||
| M2 |
Tacotron 2 + HiFi-GAN V1
| Seen Speakers | Recording | ST (GT features*) | ST | ST-SA (Proposed) |
|---|---|---|---|---|
| F1 | ||||
| F2 | ||||
| M1 | ||||
| M2 |
FastSpeech 2 + eUnivNet
| Seen Speakers | Recording | ST | ST-SA (Proposed) |
|---|---|---|---|
| F1 | |||
| F2 | |||
| M1 | |||
| M2 |
Unseen Speakers (Tacotron 2 + eUnivNet)
| Unseen Speakers | Recording | ST | ST-SA (Proposed) |
|---|---|---|---|
| F3 | |||
| M3 |
Vocoder Model Comparison
Tacotron 2 + ST-SA vocoders
| Speaker | Recording | UnivNet-c32 | eUnivNet (Proposed) | eUnivNet-H/N-G | eUnivNet-M/C-D |
|---|---|---|---|---|---|
| F1 | |||||
| F2 | |||||
| M1 | |||||
| M2 |
[1] J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” in Proc. NeurIPS, 2020, pp. 17022–17033.
(We trained the model for 1M steps using the official implementation.)
[2] W. Jang, D. Lim, J. Yoon, B. Kim, and J. Kim, “UnivNet: A neural vocoder with multi-resolution spectrogram discriminators for high-fidelity waveform generation,” in Proc. INTERSPEECH, 2021, pp. 2207–2211.
(We trained the model for 1M steps using an open-source implementation.)